# Data Engineering and MLOps
# DVC
DVC or [Data Version Control](https://dvc.org/) is an open source tool for managing data assets. It is very useful but also can be quite overwhelming to use.
The main use cases I've found for DVC are:
1. Keeping large data assets (e.g. machine learning datasets) version controlled alongside code so that you always know where the latest version of some project specific training data can be found.
2. Making sure that all intermediate and final outputs from experiments are reproducible. This is always good to know when a client inevitably asks you "ok how did you get **Y** surprising result?" or "can you just confirm that you included **X** features in your model?" DVC helps by:
1. Keeping track of file hashes used at each stage in a pipeline
2. Keeping a copy of the file content at each stage in the pipeline.
# Model Registry
A model registry is a service that provides version-control-like behaviour for ML models. There are a number of open source and commercial model registries.
### MLFlow
[MLFlow](https://mlflow.org/) is an open source model registry that provides a bunch of features including model version registration and result storage.
### SnowPark Registry
SnowPark is a container runtime environment inside Snowflake and it provides Model Registry functionality which is documented [here.](https://docs.snowflake.com/en/developer-guide/snowpark-ml/snowpark-ml-modeling)
# Data Wrangling
### DuckDB
[DuckDB](https://duckdb.org/) is a lightweight OLAP type database system written in C++ and designed to be used for EDA style activities:
[](https://wiki.jamesravey.me/uploads/images/gallery/2022-11/kqSimage.png)
**From their website: advice on when to use and not to use DuckDB**
### Polars
[Polars](https://www.pola.rs/) is a rust-based data frames library with Python bindings
[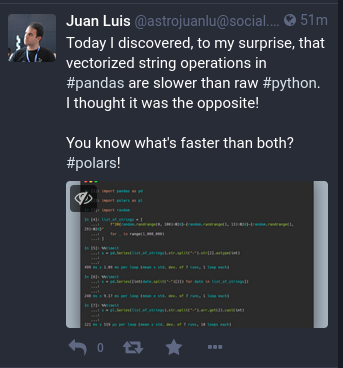](https://social.juanlu.space/@astrojuanlu/109285218527601776)
[Here is a talk](https://yewtu.be/watch?v=GvYeBHNGlvM) that Juan Luis gave about the library
# DBT
[DBT i](https://docs.getdbt.com/)s a data transformation tool with a SaaS platform and an open-core command line tool.
The tool is [widely used](https://rmoff.net/2022/11/08/data-engineering-in-2022-elt-tools/) to put the T in ELT.
Robin Moffat has written [a walkthrough/guide ](https://rmoff.net/2022/10/20/data-engineering-in-2022-exploring-dbt-with-duckdb/)on how he used DBT with [DuckDB](https://wiki.jamesravey.me/books/data-engineering-and-mlops/page/data-wrangling "Data Wrangling")
# Data Loading with Airbyte
Airbyte is a FOSS tool for mass data import and export when working with common flavours of SQL and OLAP databases.